Veľký jazykový model
Niekedy o ňom môžeme čítať aj ako o LLM (Large Language Model). Je to sofistikovaný počítačový program, ktorý je určený na analýzu a generovanie textu. Môže byť využitý napríklad na strojový preklad, rozpoznávanie reči, generovanie odpovedí a pod.
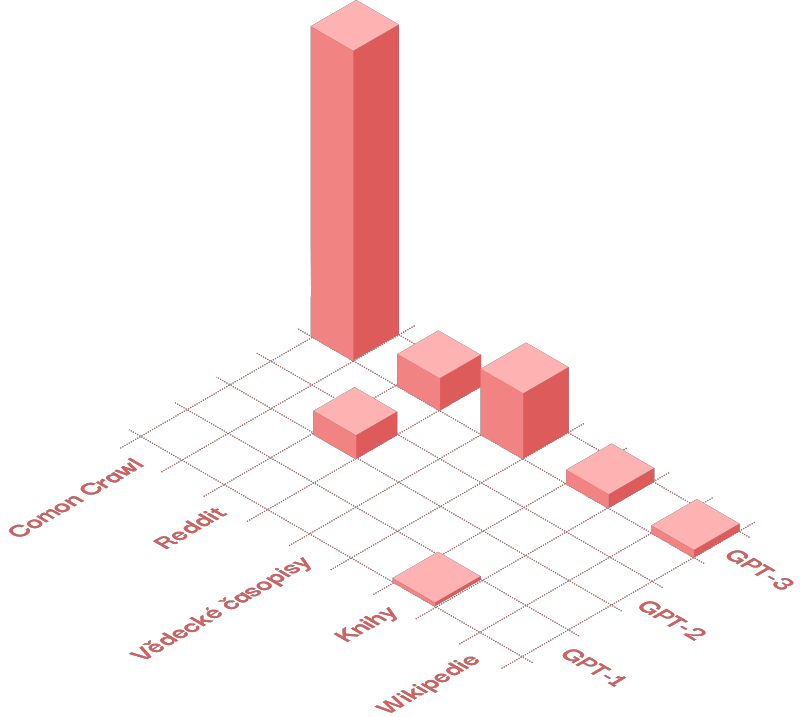
LLM sú trénované na obrovskom množstve textov, ktorým sa hovorí korpusy. Môžu to byť napríklad digitalizované knihy, články, obsah Wikipédie a ďalšie. Takto sa napríklad vyvíjal model GPT [zdroj]:
Knižný korpus GPT-1
Romantické knihy: 26,1 %
Fantasy: 13,6 %
Sci-fi: 7,5 %
Pre dospievajúcich: 6,8 %
Triler: 5,9 %
Knihy o upíroch: 5,4 %
Mysteriózne: 5,6 %
Ďalšie...
Common Crawl
Databáza Common Crawl je verejne dostupný archív webových stránok. Je vytváraná pravidelným prehliadaním (crawlovaním) webu a ukladaním obsahu.
Na obrázku vidíme korpusy, na ktorých boli natrénované jednotlivé verzie modelu GPT. Výška kvádrov predstavuje pomerné množstvo dát.
Veľké jazykové modely majú svoju vnútornú reprezentáciu nášho sveta. Je vytvorená pomocou tzv. vektorov. Predstavte si model ako obrovský multidimenzionálny priestor, v ktorom má každé slovo (token) svoju presnú polohu. Tá sa nazýva vektor a môžete si ju predstaviť ako súradnicu. Rôzne slová majú k sebe v rôznych kontextoch bližšie než k jiným.
Napríklad keď napíšete do chatbota zadanie (tzv. prompt):
Vygeneruj recept na volské oko.
slovo „oko“ sa bude v tomto kontexte nachádzať inde, než keď napíšete:
Opíš, ako vzniká obraz na sietnici oka.
Prepojenie medzi slovami
Zjednodušenú vizualizáciu prepojenia slov (tokenov) si môžete pozrieť napríklad v aplikácii Embedding Projector. Prejdite myšou na jednotlivé body a uvidíte slová. Keď na bod kliknete, zobrazia sa sémanticky podobné výrazy.
To, čo sa deje vo veľkom jazykovom modeli po vložení pár tokenov, môžete vidieť v aplikácii AnimatedLLM.
Na svete existuje len niekoľko veľkých jazykových modelov a z dôvodu nárokov na počítačový hardvér ich vytvárajú najmä veľké spoločnosti. V súčasnosti sú najznámejšie GPT (OpenAI), Claude (Anthropic), Gemini (Google), Llama (Meta), LaMDA (DeepMind) alebo napríklad DeepSeek (Hangzhou).
Proces vzniku veľkého jazykového modelu možno (veľmi zjednodušene) rozdeliť do troch krokov:
+ výber korpusov: tie by mali byť dostatočne veľké a rozmanité,
+ trénovanie modelu: model sa trénuje na dátach pomocou algoritmov strojového učenia,
+ validácia a testovanie: model sa skúša na dátach mimo trénovacej sady, upravuje sa a ďalej vylepšuje.
Nakonec je model nasadený na reálne použitie, napríklad na vedenie konverzácie (chatboty), preklad textov alebo iné aplikácie. Na to je potrebné zabezpečiť, aby sa chatbot správal k používateľom vhodne a nikomu neublížil.